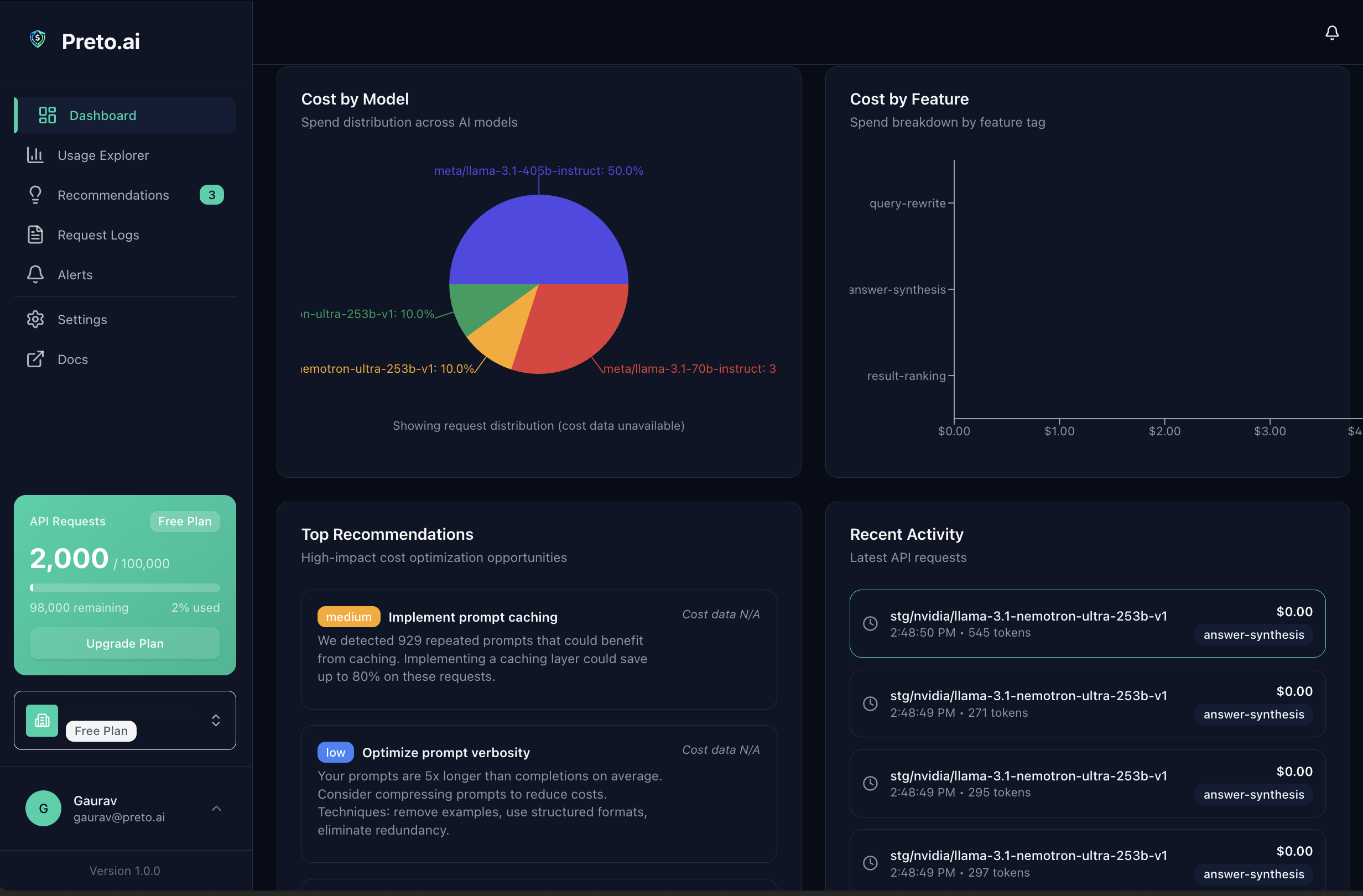
"I kept seeing teams waste 40–60% of their LLM spend on model choices they never revisited. A GPT-4 call that costs $0.06 could run on GPT-5 Mini for $0.002 — same quality. One URL change shouldn't be this hard to justify. So I built Preto to make the ROI obvious in under an hour."
Built With
Go · ClickHouse · Redis
Providers
OpenAI · Anthropic · NVIDIA · ElevenLabs · Deepgram
Performance
<50ms p95 · 5,000+ req/s